
Timetable and program:
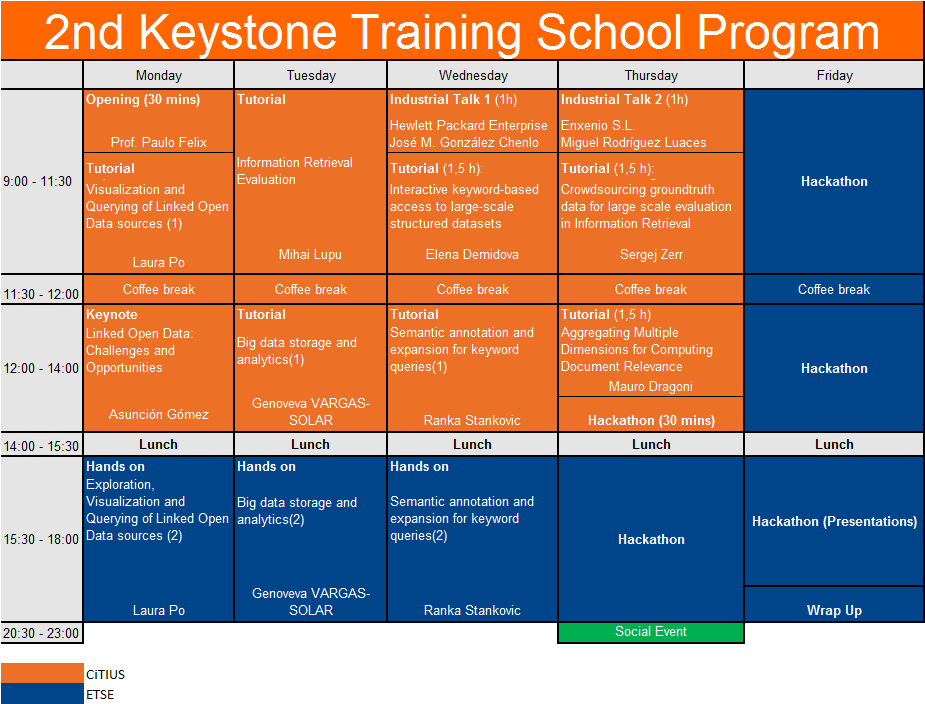
Topics of the different sessions:
Linked Open Data: Challenges and Opportunities (Keynote - Speaker: Asunción Gómez-Pérez)
Linked Data (LD) and related technologies are providing the means to connect high volumes of disconnected data at Web-scale and producing a huge global knowledge graph. The key benefits of applying LD principles to datasets are: (i) better modelling of datasets as directed labelled graphs, (ii) structural interoperability of heterogeneous resources, (iii) federation of resources from different sources and at different layers inlcuding language annotation, (iv) a strong ecosystem of tools based on RDF and SPARQL, (v) improved conceptual interoperability due to strong semantic models such as OWL and shared semantics due to linking and (vi) dynamic evolution of resources on the web.
In this talk, I will explore challenges related with the (Re)Usability of linked metadata in several domains. I will argue that for maximizing (re)use of linked metadata it is crucial to represent core aspects related with Linguistic, Provenance, License, and Dataset metadata. A proper representation of these features using W3C standards and the use of W3C best practices and guidelines for multilingual Linked Open Data: (i) produce better linked metadata that could be used later on for diagnosing and repairing other external resources; (ii) facilitate rights management, and consequently the access and reuse of metadata and data delivered under different license schema;(iii) enable navigation across datasets in different languages thanks to the exploitation of links across multilingual data; (iv) help data providers and data consumers to go a step further when cataloguing, searching and building cross-lingual applications that use open library linked metadata;and (v) increase exploitation when library linked metadata will be used with licensed (open or closed) linked data in other domains. I will also present approaches that use datos.bne.es library linked metadata with geographical information to produce new insights and innovation.
Exploration, Visualization and Querying of Linked Open Data sources(Tutor: Laura Po)
The Linked Data Principles defined by Tim-Berners Lee promise that a large portion of Web Data will be usable as one big interlinked RDF database. Today, with more than one thousand of Linked Open Data (LOD) sources available on the Web[1], we are assisting to an emerging trend in publication and consumption of LOD datasets. While the publication of data is performed by domain experts and requires specialized tools, the consumption of LOD demands simple data exploration and visualization tools in order to maximize the dissemination of data also for non-skilled users. In this context, several recent efforts have offered tools and techniques for exploration and visualization in many different domains [2]. In this talk, I will discuss the major challenges that should be addressed by the exploration tools when handling Linked Open Data, such as dealing with large size sources, considering the dynamic nature of data, providing means to customize the exploration experience of the users. Considering these challenges, several tools developed by the Semantic Web community will be presented. This part will be organized in a hands-on training session which will get an insight on how to explore a LOD source and which tools are better in which tasks. In the end, I will discuss to which extent these tools satisfy the contemporary requirements and which future developments are expected.
[1] M. Schmachtenberg, C. Bizer and H. Paulheim. State of the LOD Cloud 2014. 2014. http://linkeddatacatalog.dws.informatik.uni-mannheim.de/state/
[2] A. Dadzie and M. Rowe. Approaches to visualising Linked Data: A survey. Semantic Web, 2(2), 2011
Information Retrieval Evaluation (Tutor: Mihai Lupu)
Information Retrieval is a heavily experimental science, which has consistently relied on experimental results to drive its progress. For any researcher, young or not, it is important to have an overview of the best practice in evaluation, whether they are planning research on IR Evaluation itself or in any other Information Access-related area. The lecture will cover the fundamental issues of IR evaluation, as observed in evaluation campaigns, considering the perspectives of both their supporters and critics. The lecture is entitled IR Evaluation++ because, while focusing on the large amount of know-how present in the IR community, it also touches upon other aspects of Information Access Evaluation and puts the work in relationship with database systems evaluation.
Big data storage and analytics, including network science and graph stores (Tutor: Genoveva Vargas-Solar) The emergence of Big Data some years ago denoted the challenge of dealing with huge collections of heterogeneous data continuously produced and to be exploited through data analytics processes. First approaches have addressed data volume and processing scalability challenges. Solutions can be described as balancing delivery of “physical” services of (i) hardware (computing, storage and memory), (ii) communication (bandwidth and reliability) and scheduling (iii) greedy analytics and mining processes with high in-memory and computing cycles requirements. Due to the democratization Big Data management and processing is no longer only associated to scientific applications with prediction, analytics requirements, the homo technologicus requirements also call for Big Data aware applications related to the understanding and automatic control of complex systems, to the decision making in critical and non-critical situations. Big Data forces to view data mathematically (e.g., measures, values distribution) first and establish a context for it later. For instance, how can researchers use statistical tools and computer technologies to identify meaningful patterns of information? How shall significant data correlations be interpreted? What is the role of traditional forms of scientific theorizing and analytic models in assessing data? What you really want to be doing is looking at the whole data set in ways that tell you things and answers questions that you’re not asking. All these questions call for well-adapted infrastructures that can efficiently organize data, evaluate and optimize queries, and execute algorithms that require important computing and memory resources. This lecture will address different techniques for analysing and visualizing big data collections including a vision of the analytics process as a complex and greedy task and then visualization as out of the box solutions that can help to analyse and interpret big data collections.
Interactive keyword-based access to large-scale structured datasets (Tutor: Elena Demidova)
The data available on the Web, in large-scale Web archives, in digital libraries and in open datasets is constantly growing and changing its appearance. The structural and linguistic heterogeneity of this data, as well as its large scale, substantially restrict its accessibility to the end users. In order to supply users with relevant and fresh information on demand, effective and efficient methods are essential that are able to cope with unknown data structures and large scale data. In this tutorial, we explore methods tackling these challenges with the focus on interactive retrieval techniques for structured data that do not require a-priori schema knowledge.
Semantic annotation and expansion for keyword queries (Tutor: Ranka Stankovic)
A review of ontology based query expansion and a review of query expansion approaches. The various query expansion approaches that include relevance feedback, corpus dependent knowledge models and corpus independent knowledge models. Case studies detailing query expansion using domain-specific and domain-independent ontologies. Review and success factors in using an ontology for query expansion. A keyword-based semantic retrieval approach. The performance of the system improvement by using domain-specific information extraction and inferencing rules. Interfaces grouped in four categories: keyword-based, form-based, view-based and natural language-based systems. Combining the usability of keyword-based interfaces with the power of semantic technologies. Ontology-based framework for the extraction and retrieval of semantic information in specialised domains with modules: crawler, automated information extraction, ontology population, inferencing, and keyword-based semantic query interface.Examples of application on parallel corpora and geodatabases among other sources, using domain ontologies; WordNet; Relevance feedback.
Collective Intelligence: Crowdsourcing groundtruth data for large scale evaluation in Information Retrieval (Tutor: Sergej Zerr)
''Two heads are better than one'', this idiom exists in many languages around the world. Everyday people are collaboratively carrying out decision processes in a wide range of application cases. Interestingly, we can sometimes observe that under certain circumstances a sufficiently large group of non-experts can be smarter than a few experts. Although this phenomena, often described in the literature as a ''wisdom of a crowd'', is well known since centuries, only in the modern age this wisdom can be exploited in full by researchers, as they are able to access really large groups of people through the Internet. ?Crowdsourcing? is a recent scientific movement, dealing with aggregation of collaborative knowledge and its exploitation it in a wide range of scientific areas, such as Machine Learning or Information Retrieval.
In this tutorial we will explore, how collaborative knowledge is used for evaluation of Information Retrieval algorithms and focus on efficient methods for scalable and reliable collection of annotations through crowdsourcing and gamification.
Aggregating Multiple Dimensions for Computing Document Relevance (Tutor: Mauro Dragoni )
In the lecture, models supporting multiple criteria evaluations for relevance assessment are proposed. An Information Retrieval context is considered, where relevance is modeled as a multidimensional property of documents. The usefulness and effectiveness of such a model are demonstrated by means of two case studies: (i) personalized Information Retrieval with multi-criteria relevance and (ii) multiple layers of metadata annotations.
The possibility of aggregating the considered criteria in a prioritized way is also considered. Such a prioritization is modeled by making the weights associated to a criterion dependent upon the satisfaction of the higher-priority criteria. This way, it is possible to take into account the fact that the weight of a less important criterion should be proportional to the satisfaction degree of the more important criterion.
Experimental evaluations are also reported.


